We are Embedded Performance Computing specialists.
Based on NVIDIA’s Jetson embedded platform, we Recommend, Deliver, Support & Provide NPI services for the Embedded and Edge AI worlds. Our know how is built upon our extensive experience in the fields of Embedded, Edge AI and High Performance Computing works.
We have learned the importance of offering SW services such as Image Pipe Line & Neural Network Optimizations. We deliver Remote Management solutions and Cyber Security services for the Jetson platform.
Based on NVIDIA’s Jetson embedded platform, we Recommend, Deliver, Support & Provide NPI services for the Embedded and Edge AI worlds. Our know how is built upon our extensive experience in the fields of Embedded, Edge AI and High Performance Computing works.
We have learned the importance of offering SW services such as Image Pipe Line & Neural Network Optimizations. We deliver Remote Management solutions and Cyber Security services for the Jetson platform.
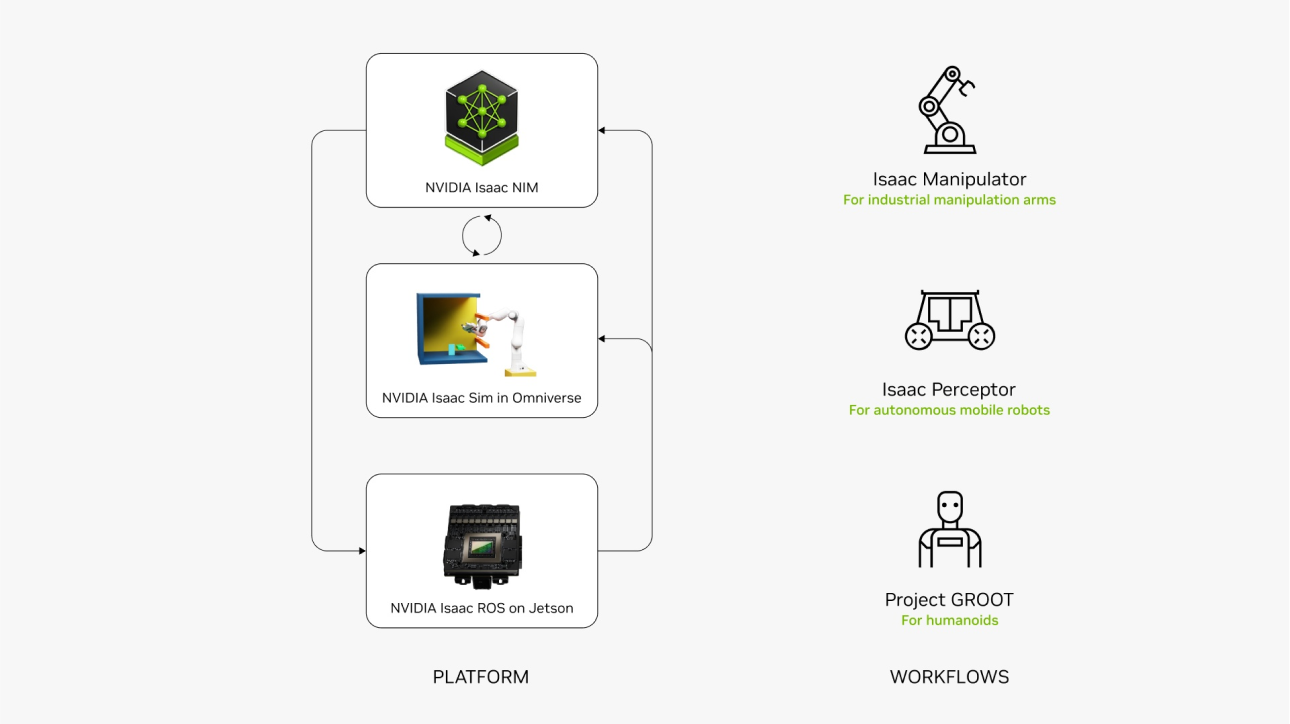
NVIDIA Isaac
The NVIDIA Isaac™ AI robot development platform consists of NVIDIA-accelerated libraries, application frameworks, and AI models that accelerate the development of AI robots such as autonomous mobile robots (AMRs), arms and manipulators, and humanoids.
Accelerate Your Product Design, Simulation, and Visualization Workflows
To create the next generation of products, which are increasingly more complex and connected, designers, engineers, and scientists are turning to NVIDIA technologies. With breakthroughs in AI, 3D virtualization, real-time simulation, extended reality (XR), and collaboration solutions like NVIDIA Omniverse™, these innovators are transforming their workflows to optimize design, speed development, improve efficiency, and reimagine our world’s future.
NVIDIA AI Enterprise is an end-to-end, cloud-native software platform that accelerates data science pipelines and streamlines development and deployment of production-grade co-pilots and other generative AI applications. Easy-to-use microservices provide optimized model performance with enterprise-grade security, support, and stability to ensure a smooth transition from prototype to production for enterprises that run their businesses on AI.

Optimize Performance
NVIDIA NIM and CUDA-X microservices provided an optimized runtime and easy to use building blocks to streamline generative AI development.

Deploy With Confidence
Protect company data and intellectual property with ongoing monitoring for security vulnerabilities and ownership of model customizations.

Run Anywhere
Standards-based, and containerized microservices are certified to run on the cloud, in the data center, and on workstations.

Enterprise-Grade
Predictable production branches for API stability, management software, and NVIDIA Enterprise Support helps keep projects on track.
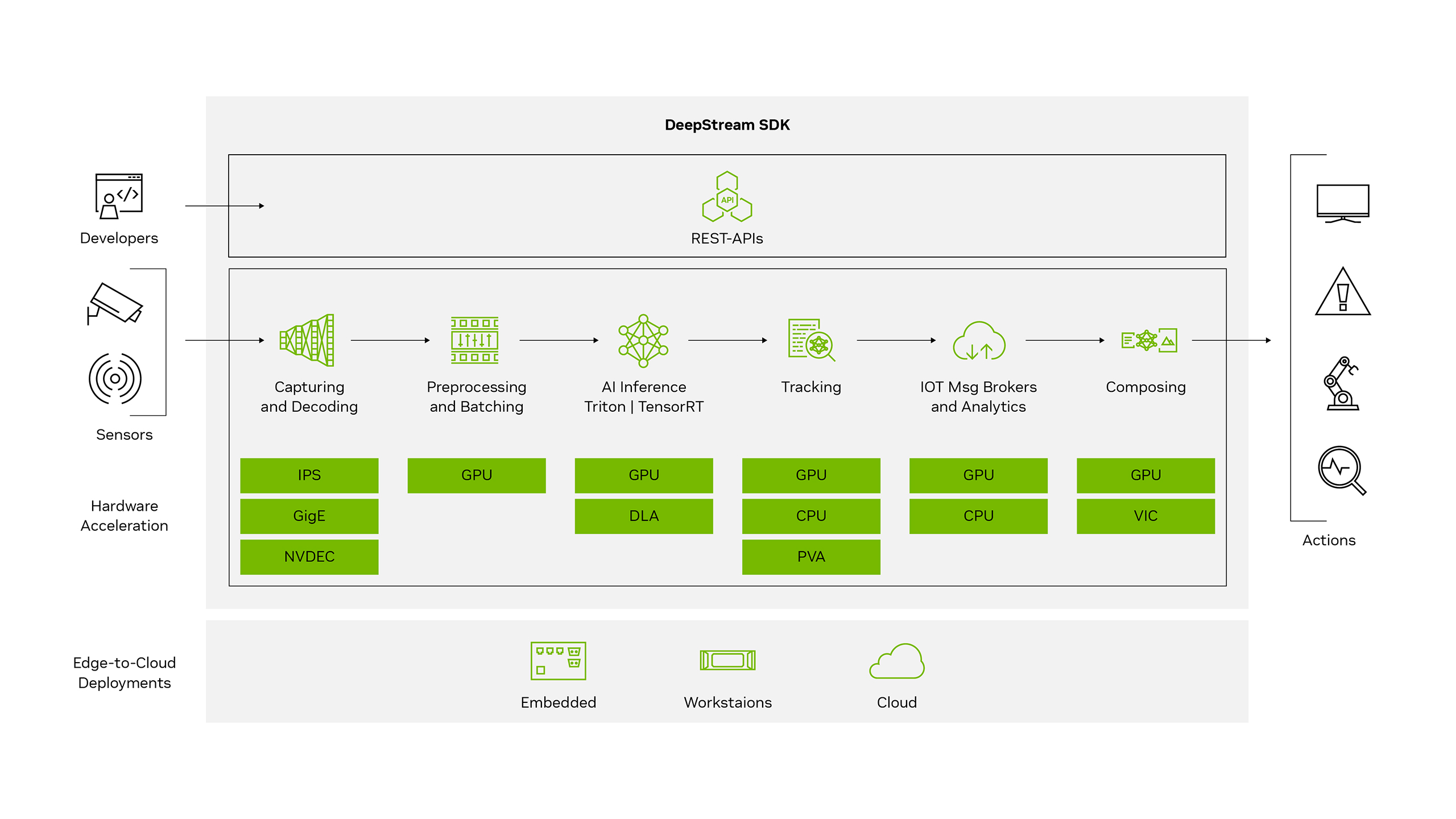
NVIDIA’s DeepStream SDK is a complete streaming analytics toolkit based on GStreamer for AI-based multi-sensor processing, video, audio, and image understanding. It’s ideal for vision AI developers, software partners, startups, and OEMs building IVA apps and services.
You can now create stream-processing pipelines that incorporate neural networks and other complex processing tasks like tracking, video encoding/decoding, and video rendering. These pipelines enable real-time analytics on video, image, and sensor data.
You can now create stream-processing pipelines that incorporate neural networks and other complex processing tasks like tracking, video encoding/decoding, and video rendering. These pipelines enable real-time analytics on video, image, and sensor data.
NVIDIA® TensorRT™ is an ecosystem of APIs for high-performance deep learning inference. TensorRT includes an inference runtime and model optimizations that deliver low latency and high throughput for production applications. The TensorRT ecosystem includes TensorRT, TensorRT-LLM, TensorRT Model Optimizer, and TensorRT Cloud.
NVIDIA TensorRT Benefits
Speed Up Inference by 36X
NVIDIA TensorRT-based applications perform up to 36X faster than CPU-only platforms during inference. TensorRT optimizes neural network models trained on all major frameworks, calibrates them for lower precision with high accuracy, and deploys them to hyperscale data centers, workstations, laptops, and edge devices.
Optimize Inference Performance
TensorRT, built on the CUDA® parallel programming model, optimizes inference using techniques such as quantization, layer and tensor fusion, and kernel tuning on all types of NVIDIA GPUs, from edge devices to PCs to data center.
Accelerate Every Workload
TensorRT provides post-training and quantization-aware training techniques for optimizing FP8, INT8, and INT4 for deep learning inference. Reduced-precision inference significantly minimizes latency, which is required for many real-time services, as well as autonomous and embedded applications.
Deploy, Run, and Scale With Triton
TensorRT-optimized models are deployed, run, and scaled with NVIDIA Triton™ inference-serving software that includes TensorRT as a backend. The advantages of using Triton include high throughput with dynamic batching, concurrent model execution, model ensembling, and streaming audio and video inputs.
NVIDIA TensorRT Benefits
Speed Up Inference by 36X
NVIDIA TensorRT-based applications perform up to 36X faster than CPU-only platforms during inference. TensorRT optimizes neural network models trained on all major frameworks, calibrates them for lower precision with high accuracy, and deploys them to hyperscale data centers, workstations, laptops, and edge devices.
Optimize Inference Performance
TensorRT, built on the CUDA® parallel programming model, optimizes inference using techniques such as quantization, layer and tensor fusion, and kernel tuning on all types of NVIDIA GPUs, from edge devices to PCs to data center.
Accelerate Every Workload
TensorRT provides post-training and quantization-aware training techniques for optimizing FP8, INT8, and INT4 for deep learning inference. Reduced-precision inference significantly minimizes latency, which is required for many real-time services, as well as autonomous and embedded applications.
Deploy, Run, and Scale With Triton
TensorRT-optimized models are deployed, run, and scaled with NVIDIA Triton™ inference-serving software that includes TensorRT as a backend. The advantages of using Triton include high throughput with dynamic batching, concurrent model execution, model ensembling, and streaming audio and video inputs.